



AI's next frontier: building and investing in Large Language Models
A series of deep thinking articles about the rapid evolving AI ecosystem


Note for mobile readers: we use many animated gifs to showcase the applications discussed and, for that reason, we recommend you use a laptop and browser for the optimal reading experience.

Why language is everything
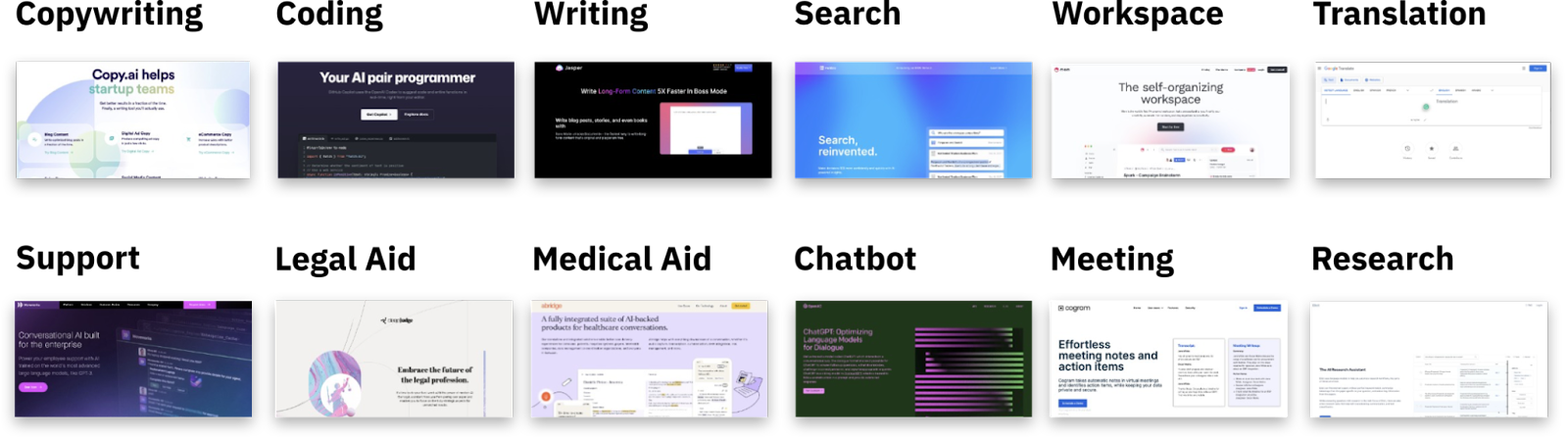
Language, the ability to write and speak, is humanity's most important invention and is what sets us apart from other species. It enables us to reason abstractly, develop complex ideas, and communicate them to one another. Almost nothing in modern civilization would be possible without it. It is, therefore, clear that Large Language Models (LLMs) will have the most significant impact in the years to come among all of the recent advancements within generative AI. The rapid rise in popularity of ChatGPT serves as an illustration of that. Other examples of what LLMs are used for include content creation, code generation, drug discovery and development, translation, search, and workplace utilities such as meeting transcription and summarization.
In short, the recent advancements in generative AI mark a new era in the field of AI where it is no longer just a research topic but also a practical tool that can be used to solve real-world problems and create value in literally every industry. Therefore, businesses must start thinking about how AI will impact them and act now to stay competitive. Companies that fail to incorporate AI into their operations will risk falling behind the curve and may struggle to survive in the long run. The key is for companies to understand the benefits of AI, evaluate its costs and benefits, and take the necessary steps to implement it in their operations. The coming few years will likely be remembered as a golden era where thousands and thousands of new generational businesses were formed.
We will dedicate this first article in our series to LLMs. We will also provide a fundamental overview of LLMs and the technologies surrounding them, followed by how they are applied in practice. This will hopefully be helpful for practitioners who want to thoroughly understand how they should apply LLMs in their businesses, as well as for investors who want to get a sufficient understanding of the field before making any potential investment decisions. While several of the frameworks that we provide (such as the categorization of different types of AI companies) are applicable to any type of Generative AI, we will mainly provide examples from LLMs.

Before you continue,
Subscribe for free to receive our next
deep articles on AI
From time to time, there comes a seminal paper that influences the direction of a research field for years to come. For LLMs, one such paper is “Attention Is All You Need” published by a team of Google researchers in 2017. They proposed a new network architecture called the Transformer, which, without going into too much detail, is highly parallelizable and computationally efficient compared to the then state-of-the-art alternatives while achieving superior performance. This means that models with the Transformer architecture are cheaper and faster to train, and the resulting models perform better. The combination of being cheaper and faster while not compromising on performance is important because it enables you to train larger models and leverage more data while doing so.
Inspired by and based on the transformer architecture, numerous well-known and famous LLMs have been developed. Examples include the Generative Pre-trained Transformer (GPT) models, Bidirectional Encoder Representations from Transformers (BERT), and XLNet.
The first papers on GPT (version 1) and BERT were both released in 2018. The following year, in 2019, the first paper on XLNet was released. Despite this, it was not until the very end of 2022 that LLMs became widely popular outside the research community due to the launch of ChatGPT by OpenAI. More than 1 million people had tried it out in less than a week after its launch. Its quick adoption by users is rare and almost unprecedented among technical products. However, it is crucial to understand that nothing groundbreaking has occurred overnight. ChatGPT, which is based on GPT (version 3.5), showcases the results following years and years of progress within the field of LLMs. In fact, the model underlying ChatGPT is arguably not even the best LLM available. However, it is fair to say that it is currently the most popular one.
Time will tell, but we guess that the most important role of ChatGPT is that of a PoC for the world to see what LLMs can achieve. Notwithstanding its initial popularity, it is not at all certain that it will be one of the dominant LLMs that will gain widespread adoption for practical use cases for reasons that we will elaborate upon during the remainder of the text.
Foundation vs. Specialized LLMs

Foundation large language models are trained on a large corpus of publicly available text data (for example, from Wikipedia, news articles, Twitter, online forums, etc.). Since the models are trained on data from an extensive range of topics and contexts, they are not specialized in any particular domains or tasks. Examples of foundation LLMs include GPT-3, Jurassic-1, Gopher, and MT-NLG.
While applications built on top of foundation AI models such as ChatGPT are very popular currently, we predict that the most value of LLMs will come from models that are specialized within certain domains and/or tasks. This is because specialized models often perform better in their area of expertise compared to foundation models of the same model size. This means that foundation models need to be larger, with accompanying higher cost for inference and larger memory footprint, to even have the chance to achieve the same performance as a specialized model in the latter’s area of expertise.
One of the reasons specialized models perform better than foundation models relates to the aspect of model alignment, which represents the degree to which the output of an LLM corresponds to the goals and interests of the model user. A high model alignment implies that the answer is correct and relevant, i.e. it actually answers what is requested from it. Since a specialized model only focuses on a specific domain or set of tasks, the degree of model alignment is usually higher in its specialization area compared to foundation models.
There are different ways to specialize a model. One approach is to specialize a foundation model by further training it on data that is relevant to the domain(s) and/or task(s) of interest. For example, a foundation model might be OK at answering questions regarding the banking industry in general. However, if you want to build a chatbot that you offer to the banking industry, that performance level might not be sufficient. Then, you might resort to further train the foundation model on a dataset relevant to the banking industry to make it domain-specific. A particular bank might, in turn, want to leverage the chatbot in their customer service to automate their simpler errands. To achieve this, the bank might want to further train the domain-specified model on proprietary data from its own actual customer service conversations. By doing so, the LLM can learn how this particular bank deals with errands based on its policies and guidelines. Different banks might have very different policies and guidelines.
Since an AI model that is specialized within a certain domain and/or task does not need to be good at totally different and unrelated domains and/or tasks, the foundation models that are used as bases for further training do not need to be as large. By having smaller models, the inference cost and memory footprint will be lower and smaller, respectively. In other words, foundational models that are much smaller than the largest available ones might become the go-to choice as foundations of specialized models.
How are LLMs improved?
To better understand the capabilities and limitations of LLMs, it is important first to have a better understanding of how they can be improved. The three main drivers are architectural improvements, larger models, and more training data. Let’s go through each of them.

Architectural improvements are key, but breakthroughs are hard to predict
Architectural improvements such as the invention of the Transformers architecture in 2017 can boost the performance of LLMs without increasing model complexity or the amount of training data used. Most of the state-of-the-art LLMs currently being built are still based on transformer network architectures (very similar to the one introduced in 2017). Although it has known limitations, for example in the form of quadratic time and memory complexity due to its self-attention, no actual update to the architecture has yet been widely adopted. With this said, there has been tremendous effort devoted to improving the architecture and coming up with, for example, so-called efficient Transformers to eliminate these identified limitations.
Incremental improvements upon existing state-of-the-art architectures, such as the effort to develop efficient Transformers, will collectively contribute to gradually push the boundaries of the model performances over the coming years. In addition, every once in a while, seminal architectural improvements such as the invention of the original Transformer architecture will be made, which contributes to a significant step change improvement of the model performances.
While increased model sizes and amounts of training data are relatively easy to plan and execute on, architectural improvements are not. Instead, they follow the patterns within traditional research and development activities, with bold and innovative ideas being tested without any guarantees of results. Therefore, this category of performance improvements for LLMs is the trickiest one to rely on. It is also the norm for both incremental improvements and more radical breakthroughs of architectural improvements to be published and shared with the rest of the research community. This implies that improvements within this category are not necessarily something that can be used as a long-term competitive advantage over other companies and competitors who are also building LLMs - other than being first on the market with the improved model. As an example, OpenAI’s LLMs build upon the Transformer breakthroughs that were invented and made publicly available by Google Brain in 2017.
Building larger models has been a popular approach historically
So far, most of the effort to improve the performance of LLMs has been focused on increasing model sizes. During the last few years, this has partly been driven by a paper released by Open AI in 2020, which established the scaling law relationship between increased model size and increased model performance. The paper concluded that the majority of the budget to train models should go towards making them bigger. The figure below from Machine Learning Model Sizes and the Parameter Gap shows the clear trend of significantly increased sizes of language models over the years.

Prior to 2019, most LLMs were in the hundreds of millions of parameters. During 2019, OpenAI released GPT-2 which contains 1.5 billion parameters. During 2020, Google and Microsoft released T5 and Turing NLG, which contain 11 and 17 billion parameters, respectively. In mid-2020, OpenAI released GPT-3 containing 175 billion parameters. Since then, even larger models have been built, such as Jurassic-1 by AI21 consisting of 178 billion parameters, Gopher by DeepMind consisting of 280 billion parameters, MT-NLG by Nvidia and Microsoft consisting of 530 billion parameters and WuDao 2.0 by Beijing Academy of Artificial Intelligence consisting of 1.75 trillion parameters.
The main reason for why the increased size of an LLM can boost performance is that it increases its capability to model our complex reality. The Transformer architecture has been an important enabler for training larger models due to its relatively fast and cheap training. However, larger models entail higher training and inference cost, everything else equal. They also leave a larger memory footprint, which means that they need to be deployed on larger hardware. Therefore, if you have use cases which are sensitive to inference cost or memory footprint, the other approaches to improve the performance of the LLM might be preferred over growing the size of the model.
The race for more training data
An underemphasized approach to improve model performance is to focus on the data it's trained on - both in terms of quality and quantity. In a recent paper from 2022 authored by a team at DeepMind, the importance of the size of the models versus the amount of training data was investigated. The authors concluded that most language models are significantly undertrained. This means that LLMs would significantly benefit by being trained on larger datasets without increasing the model sizes. By training a relatively smaller LLM (that they named Chinchilla) containing 70 billion parameters, but with 1.4 trillion training tokens, the research team managed to construct a model that outperformed larger language models such as GPT3, Gopher, Jurassic-1 and MT-NLG, all of which have between 175-530 billion parameters but which have only been trained on 270-300 billion training tokens (please see the table below). In other words, we are most definitely going to see a race to collect bigger datasets with the end goal of improving the performances of language models.

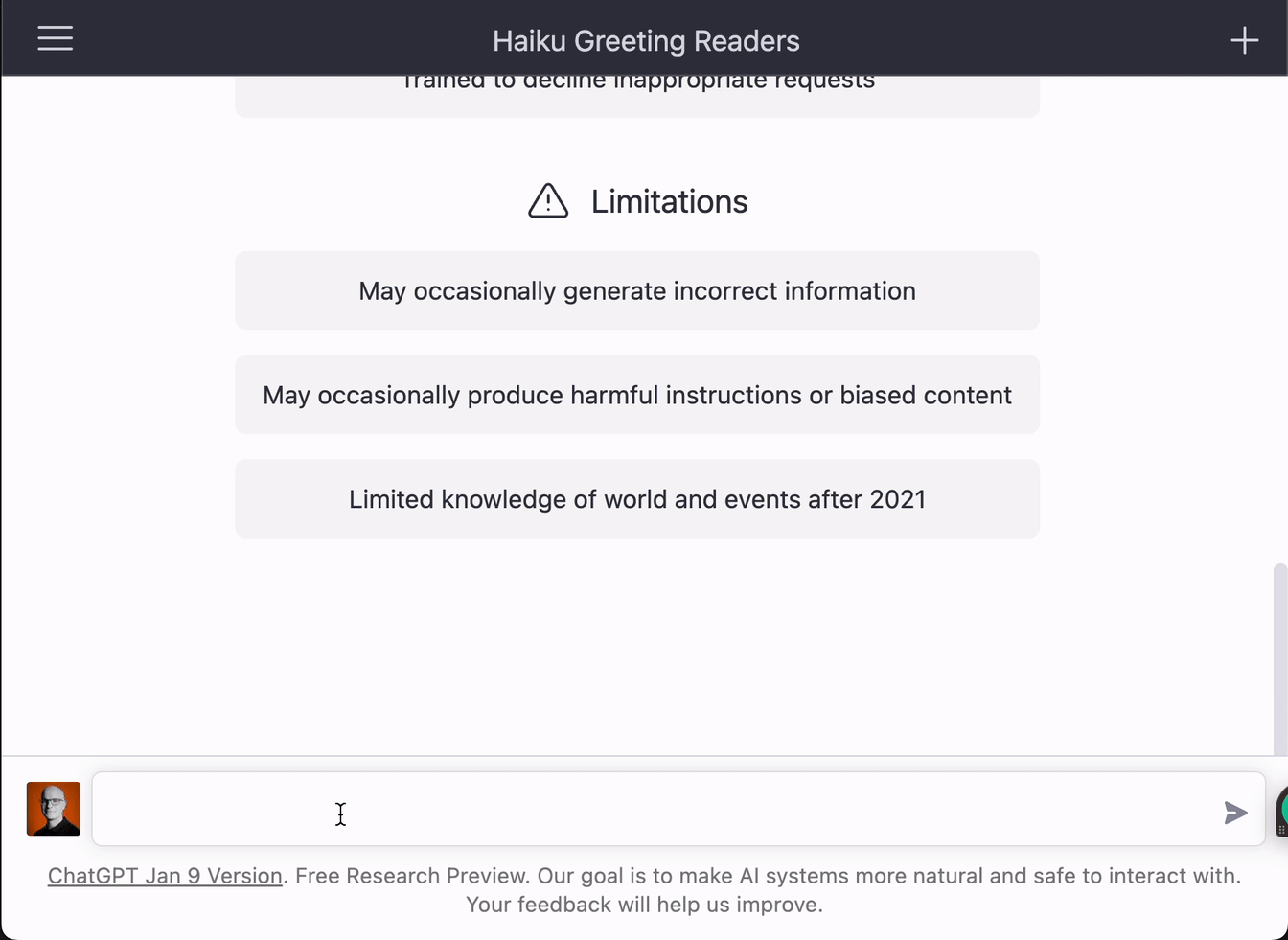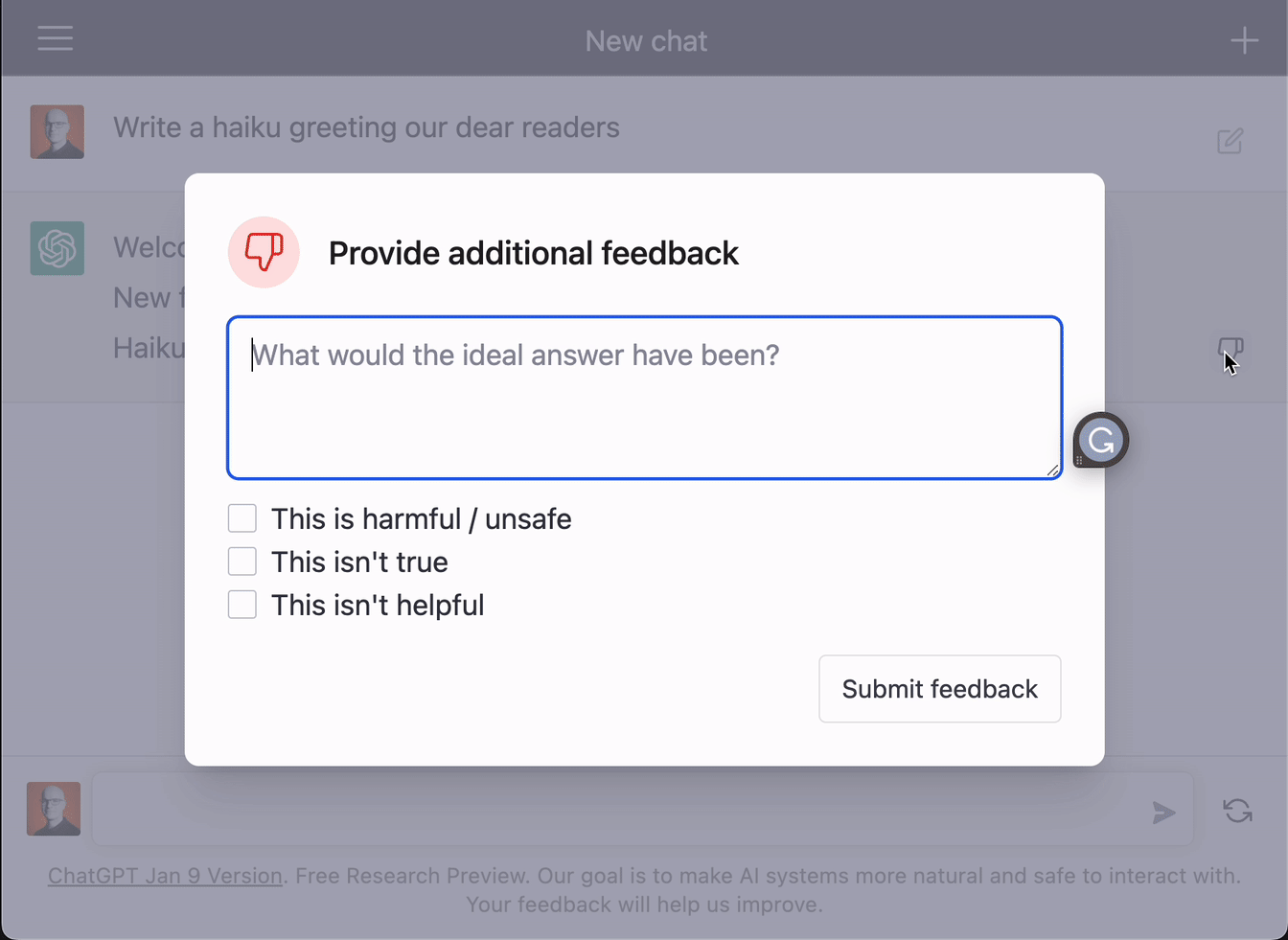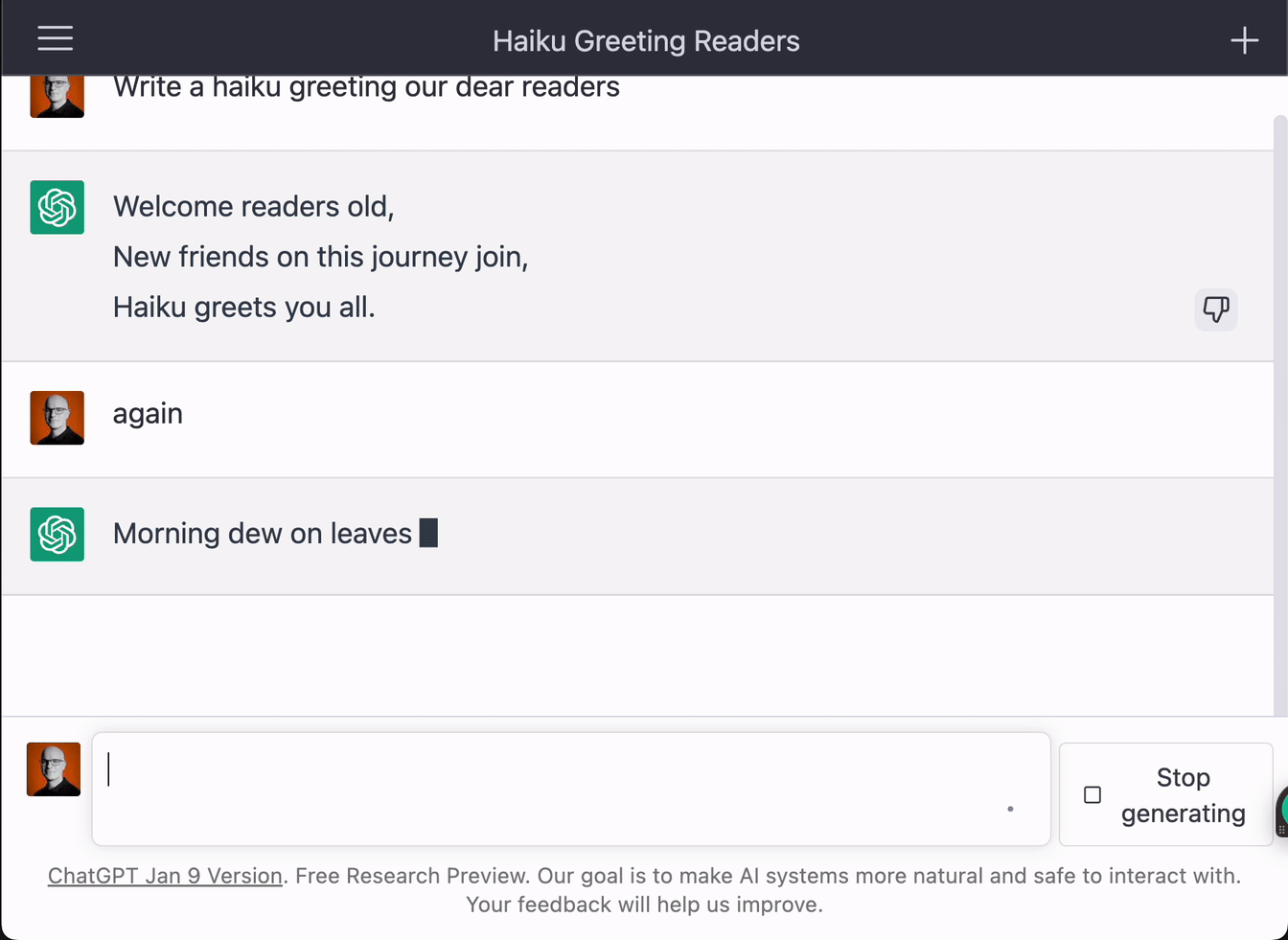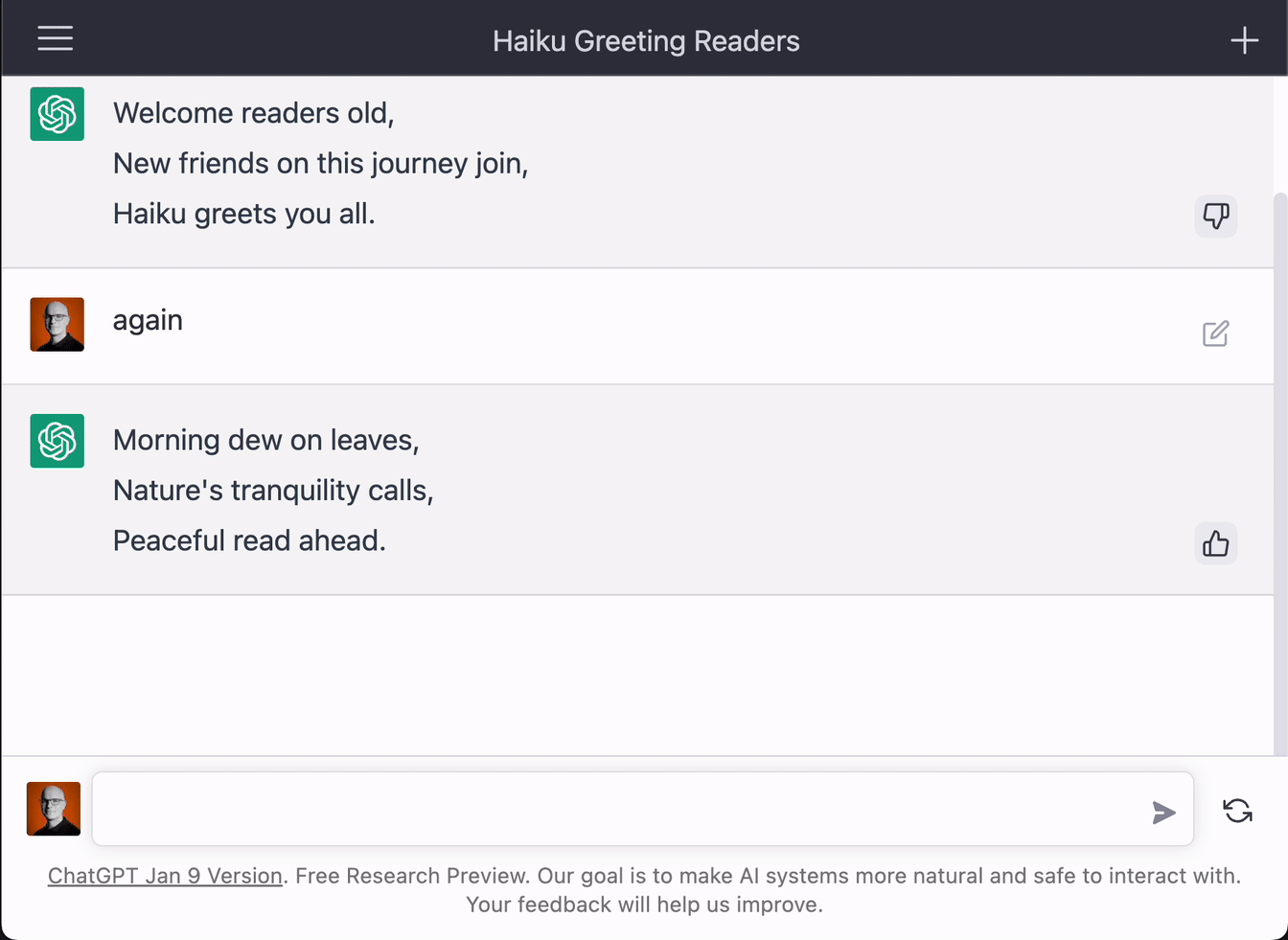
Another way in which more training data can be leveraged to improve the performance of LLMs is through reinforcement learning. In 2017, a team at OpenAI released a new class of reinforcement learning algorithms called Proximal Policy Optimizations, which is currently considered to be the state-of-the-art approach in the area. It performs at par or better than the alternative methods while being much simpler to implement in practice. The LLM behind ChatGPT has been fine-tuned by a process called Reinforcement Learning through Human Feedback, which takes place in several steps. In the first step, data consisting of human-provided “ideal” answers for different prompts is used to fine-tune the LLM through supervised learning. In the second step, the LLM provides several answers for each prompt, which is then ranked by humans. This ranking is used to train the reward model. In the third and final step, the Proximal Policy Optimization model is applied to optimize the reward model of the LLM. By leveraging reinforcement learning, the model can be steered towards providing more correct, unbiased, and less toxic answers. All in all, the LLM becomes more robust. In fact, this is one of the main reasons why OpenAI has released ChatGPT for “free public trial”. You pay by providing training data. Next to each reply generated by ChatGPT, you can press “thumbs up” or “thumbs down” to rate the response of the LLM. Regardless of what you press, a box pops up where you can provide what the ideal answer should have been, which is exactly the data you need in the first step of the reinforcement learning process.
In theory, any company could create a good LLM with sufficient funding and the right talent. As already mentioned, the knowledge of how to do so in terms of architectural design is not a guarded secret. However, we predict that the tech giants of the world will have a huge competitive edge when it comes to building the best performing LLMs due to their access to and ability to curate training data in general and for the Reinforcement Learning part in particular, to further improve and fine-tune their models. A lot of the differentiation is going to come from the data that these companies have access to for training. Companies such as Google, Microsoft, Meta, Amazon, Alibaba, and Tencent have billions of users across their different services, through which they can find innovative ways to capture relevant data for training purposes.
As opposed to improving the performance of LLMs by increasing the size of the models, training of a model with more data does not result in higher inference cost or a larger memory footprint when the model is being used. However, you will face other big challenges. One of the most crucial challenges is the fact that datasets with billions, let alone trillions, of training tokens are very difficult to document and validate in a good way, making them risky to deploy from an (in)correctness, bias, and toxicity perspective. Reinforcement learning might be able to counterbalance parts of the issues with regard to (in)correctness, bias, and toxicity to some extent, but it is very difficult to fix the issues in all domains and areas in which the LLM can provide answers.
Different types of AI companies
With the recent hype wave in generative AI, many companies are once again positioning themselves as “AI companies”. However, we see that the importance of AI for the product and differentiation of these companies, as well as which part of the AI tech stack they mainly operate in, might vary substantially. Based on this, we have divided the companies into five different categories: AI Core, AI Enabler, AI Native, AI Featured, and AI Powered.

AI Enablers are companies that operate at the bottom layer of the AI tech stack, providing infrastructure, tools, and data for building AI models. AI Core companies, who are building the actual models and selling them as their main products, rely on the services provided by AI Enablers to perform a variety of tasks related to model building. These include data acquisition, model training, model engineering, and model testing. At the application layer, we find the AI Native and AI Featured companies. They consume the AI models provided by the AI Core companies and differ in the sense that the main value proposition of AI Native companies relies on AI models, whereas AI Featured companies use AI models to add features to already existing products. At the top layer of the AI tech stack, we find the end users which we call the AI Powered companies.
AI Enablers provide the necessary infrastructure, tooling, and data to build AI models
AI Enablers are the companies that provide technologies necessary for building AI models. Given the large size of generative AI models, it is important to ensure that you have robust infrastructure that can handle the workload. In addition, tooling for MLOPs to aid in the building of AI models is required. One of the most interesting types of AI Enabler companies are the ones who provide the training data and/or tools related to the acquisition of it, since the data is an important factor for the performance and differentiation of the models.
Starting with infrastructure
Most LLMs rely heavily on cloud providers for model training and deployment. All three major cloud providers have customers who are significant players in the field of LLMs. For example, OpenAI is leveraging the Microsoft Azure stack, DeepMind is naturally building on top of the Google Cloud stack and Stability.ai has chosen Amazon Web Services as its primary cloud provider.
The rise of LLMs is only going to increase the need for the storage and compute services provided by these cloud providers. If you think about the rise of LLMs as an ongoing gold rush, the cloud and storage providers can be seen as the owners of the land to which people are rushing. It would make total sense for them to cater for the builders of LLMs in the best possible way so that they become the provider of choice for everything when it comes to compute and storage.
The cloud providers will also become important distribution channels, for example through their respective cloud marketplaces. This will make it very easy for customers who are already on the cloud to consume the models. In fact, just the other day, Satya Nadella of Microsoft revealed that ChatGPT will be available through the Azure OpenAI service. We are convinced that we will get to see many more of these examples going forward.

For a cloud provider to become competitive, it needs to focus on multiple factors including the speed of training and serving (i.e. running inferences) the models, and the cost to do so. For example, Cerebras Systems is focusing on providing compute for deep learning applications. They try to offer lower prices for training and serving deep learning applications, including LLMs, while doing it up to an order of magnitude faster than the common alternatives. Depending on the size and architecture of the model as well as the amount of training data, the cost and time for training can amount up to tens of millions (USD) as well as hundreds of days respectively. Therefore, savings on cost and time will remain important factors going forward. In an interesting turn of events, we are seeing Blockchain miner companies such as Hut 8 Mining in Canada repurposing their hardware for AI model training and serving, a transition that will potentially speed up the entering of new actors in the area.
Another important aspect regards the convenience and ease of use. Cloud providers that have underlying hardware optimized for training deep learning models in general and LLMs in particular will require less manual tweaking of the users. In addition, the massive compute clusters that have been used to train many LLMs are normally leased in multi-year contracts. Alternatives with greater flexibility in terms of shorter-term leases will be another compelling factor for consumers.
Tools for model engineering, development, and testing
MLOps (Machine Learning Operations) is a set of practices and processes that aim to integrate machine learning models into the software development lifecycle, with the goal of maintaining high performance and reliability of machine learning models in production environments over time. For LLMs, this includes model engineering, development, and testing.
During the model engineering and development phase, machine learning researchers and engineers usually use libraries and frameworks such as TensorFlow (released by Google and built on top of Python), PyTorch (released by Meta and built on top of Python) and Keras (released by Google and built on top of Python). After the models have been developed, it is important to test them before deployment.
LLMs, just like any other machine learning model, encode the information in the training data. During inference time, this information is decoded. Training data is mostly produced by humans (written dialogues and texts) - and is therefore likely to be biased. We all still remember the Microsoft chatbot that was trained on actual human dialogues through Twitter data and became racist within a few hours. Furthermore, the internet (from which we collect a lot of our training data for LLMs) is filled with misinformation. Unless the data quality validation step has identified and mitigated biases and incorrectness in the training data, the models risk perpetuating and scaling up factual incorrectness and human biases. It is fair to say that the current ecosystem of companies for scalable and automated monitoring and validation of unstructured data in the form of text is early-to-non-existing. To keep up with the demand for such services as LLMs become increasingly popular, we will certainly need some automated approaches for carrying out these tasks. Therefore, we expect to see a lot of activity in this area going forward. Maybe, there will even be LLMs focusing on assessing the quality and validity of text data?
When it comes to model testing, there exist widely accepted benchmarks to evaluate the performance of LLMs. One such example is Holistic Evaluation of Language Models (HELM), which is provided by a group of researchers based at Stanford. HELM is constructed to be broad in coverage and measures various metrics such as accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency. Despite this, it still does not cover the full picture of the actual model performance. It has been reported several times that models that perform well on benchmarks might perform poorly when you actually test them out - a great example of this was provided by Frasher Kelton (Head of Product at OpenAI) in a blog post. When a model becomes better at a certain task, it might become worse at another. In addition, metrics that are important in practice include inference cost and latency, which has to be weighted against the performances on metrics such as accuracy, fairness, toxicity, etc. Due to this situation, Kelton writes that the state-of-the-art is “testing by vibes”. “You sort of poke around to get a ~feeling~ and once you’ve spelunked enough you yolo into production”. Obviously, this is not a desired situation. Therefore, we will likely see several large companies emerge in this category.
Data Acquisition
Data acquisition starts by sourcing large datasets of text. Typically the initial batches of data come from publicly available and free data sources, which you for example can find in model hubs such as Hugging face. They can contain thousands of datasets containing millions or even billions of words each. Where the user terms allow for it, you can also crawl websites and applications for text data. Interesting potential websites and applications for that include Wikipedia, blog posts, forums, Linkedin and Twitter. On top of the publicly available and free data sources, most builders of LLMs continue to collect additional data. Here we highlight three main strategies for this: data labeling, generation of synthetic data, and data collection through feedback loops.
Examples of data labeling companies include Scale.ai and Labelbox.com, as well as the open-source alternative Labelstudio. These companies provide tooling for the labeling of data in an efficient way. One prediction we make is that providers of labeling technologies will integrate LLMs to propose labels for users, who then can focus on double-checking and approving rather than doing the actual labeling from scratch. This would automate and speed up some of the most time-consuming parts of the data labeling process, leading to an exponential growth of labeled data.

Synthetic data regards the generation of artificial data. One of the most common use cases of synthetic data is when privacy requirements limit you from leveraging the raw data in its original form, forcing you to either discard it or come up with some clever way of anonymizing it while still preserving the information of interest. If you choose the latter, you are dealing with synthetic data. Two examples of companies in the space are Mostly and Hazy.
As described in section “The race for more training data” above, Reinforcement Learning through Human Feedback is a method through which the models can improve substantially. However, to perform reinforcement learning, a certain type of training data is required. For example, in the first step of the reinforcement learning process, you need to provide desired answers for different prompts. This data is model-independent and can be provided by third-party data vendors. The next step of Reinforcement Learning through Human Feedback consists of a human ranking different answers by an LLM for a certain prompt. This step is dependent on the model and requires someone to rank answers from the actual model that you want to improve. We are likely to see companies emerge which will offer datasets for the first step and consulting services for the second step. Tools that facilitate and make it easier to collect and provide such training data are also emerging, since the ease of which one can provide such data will matter if you want to collect it at a large scale. Humanloop is an example of a company doing just that through its offering of software development kits for capturing AI answer feedback from users.
Concrete examples of these feedback loops can be observed in ChatGPT as well as Jasper.ai. As previously mentioned, ChatGPT offers the users to provide “thumbs up” or “thumbs down” as feedback for a generated answer. Jasper.ai allows for even more nuances in the feedback process by providing you the options to give a text thumbs up, thumbs down, mark as favorite, delete the entire text, or make edits and modifications. The edited texts can serve as a proxy for the answer to the question “What would the ideal answer have been?”.

Core companies build the Models
AI Core companies are focused on building the actual LLMs and commercializing them as a main stream of revenue. OpenAI is currently the most notable example, but many others exist. Three examples include AI21, Anthropic and Cohere. Please see below for examples OpenAI’s, Cohere’s, and AI21’s respective API playgrounds and outputs.
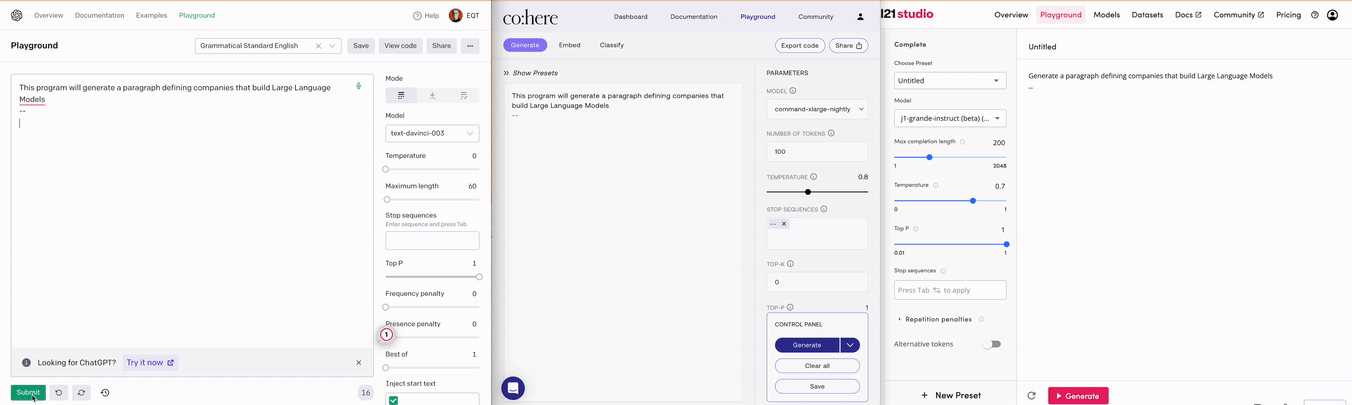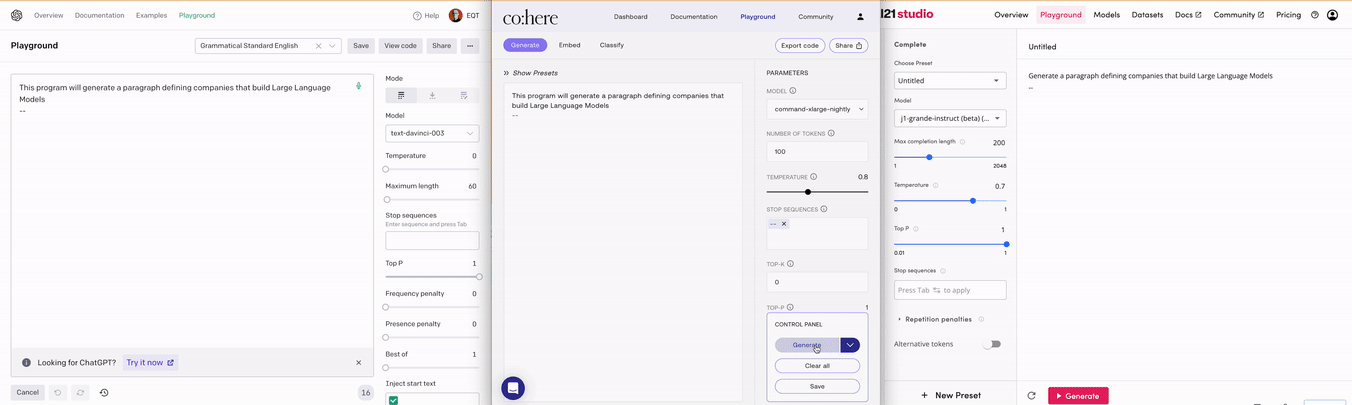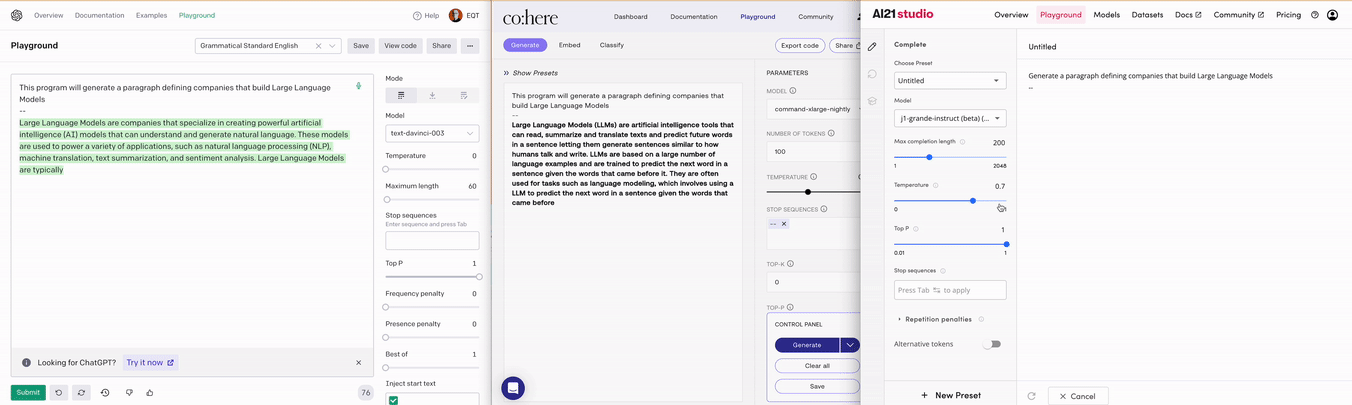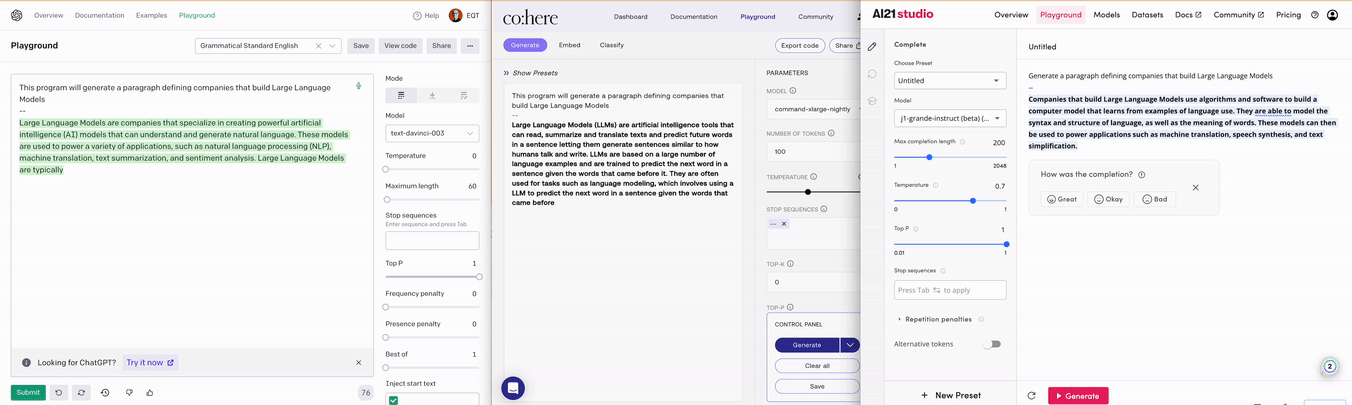
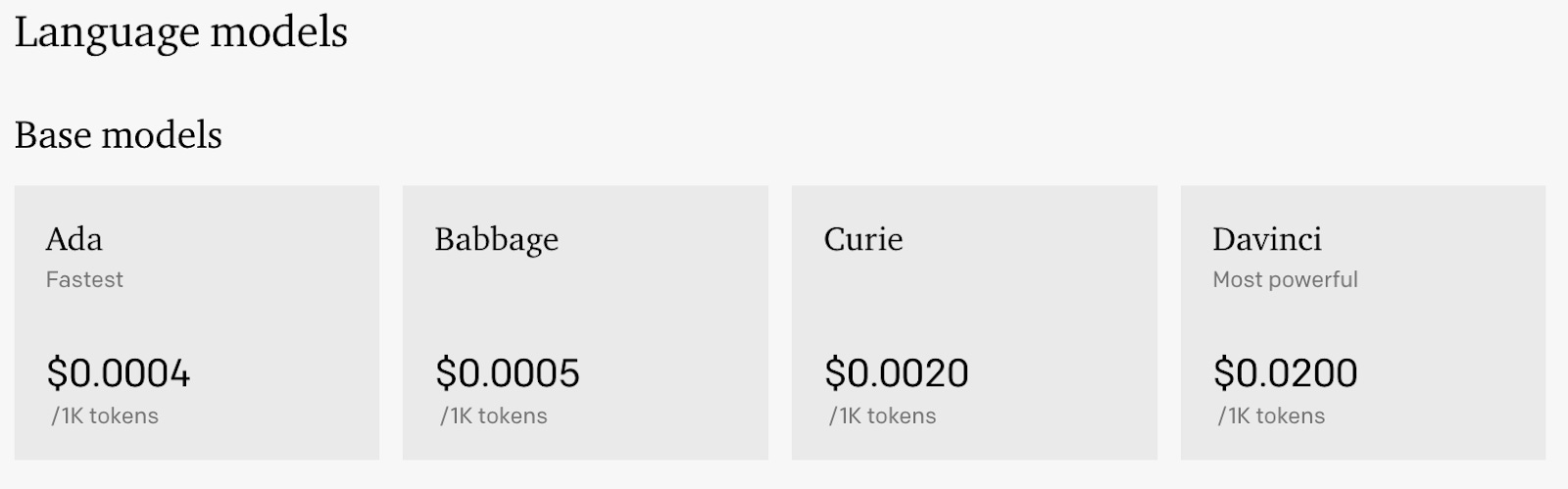
An AI Core company can either be close or open source. Close source companies protect their models by hiding them behind API calls. The most common way for close source companies to charge their customers currently is per API call. Please see the screenshot below of OpenAIs pricing for GPT-3. Depending on the performance of the model that you want to use, the cost per API call differs, where better models are more expensive than more basic ones. There is also differentiation in terms of inference speed in case you have requirements on latency for your use case. You can in other words choose the level of performance of the LLM that you think is necessary for your use cases and balance that with the associated cost.
Companies such as Jasper.ai, who start off by building their entire product on top of a close sourced LLM built by an AI Core company, do not own one of their most important IP in the form of the actual LLM. That is one of the main risks for these companies, since it does not allow them to control the models and for example specialize them in a way they see fit. In addition, close sourced models are often more expensive than open source alternatives that you could host yourself.
AI Core companies that open source their models do not have these concerns. However, even when provided the code of an LLM, many companies will not have the competency to put the model into production and serve it in a robust and scalable manner. Therefore, the open source providers usually monetize via model hosting services. Examples of organizations that are currently focusing on building open source LLMs include Eleuther, Together and BigScience/Huggingface. It is also worth noting that Google and Meta have opted to make many of their models open source.
Currently, most AI Core companies provide foundation models that are not specialized. In line with the predictions that we have made above in section “Foundation vs. Specialized LLMs”, we predict that most value of LLMs will come from specialized models. Therefore, an important stream of revenue for AI Core companies - both close and open source - will come from services that allow customers to train specialized models on top of foundation models with their own data. AI Core companies will also offer more and more specialized models right off the bat. One such example is AlphaFold, which has focused on the domain of protein structures.
AI Natives and AI Featured companies build AI applications with great UX
It is important to keep in mind that the majority of consumers of LLMs are not experts in AI. Therefore, just giving people access to the API of an LLM will not necessarily help them solve any problems. That is why the UX is highly important and will become even more so as foundation AI models become more commoditized over time while specialized models become easier and easier to create due to the emergence of companies that facilitate the model specialization processes. A lot of the differentiation is then going to lie on the UX-layer.
A clear example of the importance of the UX is the journey of the copywriting tech company Jasper.ai, which raised 125 million USD at a 1.5 billion USD in an A round 18 months after founding. At that point in time, it is rumored that they had already managed to acquire close to 100 000 paying customers and reach an ARR of roughly 75 MUSD. What Jasper did initially was to build a great UX on top of OpenAI’s GPT-3, which was accessed through APIs. In other words, Jasper did not build any of the LLMs themselves initially. Instead, they focused on making the GPT-3 APIs compelling and accessible for its target audience through offering an application which they designed with, among other, the following questions in mind:
How should the prompt input field for the GPT-3 API look like?
How should the output be presented? How many suggestions should be presented at once?
How easy is it for the user to store and rank different alternatives?
How does the tool fit into the rest of the workflow of generating text copy for a copywriter?
Competitors to Jasper.ai such as Copy.ai exist started around the same point in time and also built on top of OpenAI GPT-3 APIs initially, but their traction among end users has been much lower. This may be due to multiple factors, where the UX is a major one.
An important question to consider is: how independent can the UX layer be of the underlying LLM? Can you just switch out an underlying LLM of an application for another one without affecting the UX negatively? For incremental improvements of the LLMs (such as a model trained with more data, being fine-tuned or specialized), the UX layer will most likely not be heavily affected in a negative way (rather the opposite). However, for more radical step-change improvements of LLMs, the implications can be much bigger. For example, most LLMs currently only take a prompt from a user and then give back responses. They would benefit from asking clarifying questions before coming up with answers to make them as relevant as possible. One could say that companies that build applications on top of LLMs are creating great UX to compensate for deficiencies of the underlying models. The fact that GPT-3 does not ask for clarifying questions and does not always give perfect answers has given rise to companies such as Jasper, who have designed their product to compensate for exactly these deficiencies by providing several answers and allowing the users to easily modify and rank the answers. However, as these deficiencies get fixed directly in the underlying LLMs, the problems that these companies have spent resources and time on compensating for in the application layer will disappear. When that day comes, the question is if they provide sufficient value-add to remain in business.
Depending on how important the AI model is for the value proposition of the product, we divide companies on the application layer into two categories: AI Natives and AI Featured.
AI models as a core value proposition in the product - AI Natives
AI Natives are companies whose entire value proposition is based on the application of AI models such as LLMs. However, they do not build their own AI models. One example of this is the previously mentioned Jasper.ai. Another example comes from Elicit.org which has created an UI that allows users to explore a corpus of all the Scientific publications using natural language. They leverage the commercial version of GPT and have now started working on alternatives, leveraging Google’s T5 and Anthropic both for cost and performance benefits.
The defensibility of AI Native companies sparks a great debate. A key question is: How defensible is your business if you “only” provide an UI with great UX on top of someone else’s AI model? For example, how viable would it be to start companies such as Jasper.ai and copy.ai if ChatGPT already existed? Regardless of the answer to the question, we have seen several cases of such companies being able to gain a lot of customer traction quickly based on which they are able to raise significant amounts of funding. With the secured funds, they are able to recruit teams to build foundation models themselves and go deeper into the tech and actually own it. This is a category where speed and innovation matters to survive - you can get started very quickly by relying on someone else’s LLMs, but you also need to be quick to adapt to survive.
AI models to improve existing product(s) - AI Featured
Companies in the AI Featured category integrate AI models to create additional feature(s) on top of their existing product(s). At least initially, the AI feature(s) do not take a center role in their products. One example is the productivity tool Notion, which is primarily a note-taking tool but which recently added a shortcut for generating text from a prompt (basically a simple API call to OpenAI). While not being a core aspect of the tool, the feature is a valuable addition for Notion users since it allows them to get help with text generation directly in the tool, something they would otherwise have had to go elsewhere to get access to and then copy-paste into Notion.

Other examples of AI Featured products include Google Docs, which offers auto-complete functionality. Although the main value proposition of Google Docs is not related to the auto-complete functionality, it is a highly appreciated feature which can enhance the productivity of its users. Another example is Canva, which is a tool for creating presentations. By leveraging AI models, both the text and graphics of the presentations can be auto-generated based on user prompts and feedback.
As discussed above, a great UX is crucial for the success of AI models. One important ingredient to provide a great UX around an LLM is to integrate it deeply into existing workflows of the task that you are trying to solve with the LLM. AI featured companies that manage to integrate AI models in a sensible way into their products usually do just that. As a result of this, we expect that many AI Featured companies will become the winners in their respective categories.
With that said, without pointing out any names, we do see that there are quite some companies that have started to integrate AI functionality into their product where it makes little to no sense, meaning that the AI feature adds little to no value to their users. The purpose for these companies to implement AI features is most likely to ride the Generative AI hype-wave. Therefore, it is important to distinguish between sensible and non-sensible AI featured companies.
Intelligent organizations and augmented humans - AI Powered companies
Companies that consume AI products, but do not offer any AI applications or AI models themselves, belong to the category of AI Powered companies. This is currently the biggest category and we foresee that every company will become an AI Powered company in the near future, not least because most products and services will contain AI features of some sort. We foresee that there are two steps in which companies become AI Powered.
In the first step, individuals within organizations decide to leverage AI products on their own initiatives to become more productive. For example, a marketing manager within a company might leverage Jasper or ChatGPT for writing text copy. An account executive might leverage an LLM to generate customized emails for different leads as a part of the sales process.
In the next step, AI products are leveraged in a much more systematic manner. The initiative to leverage AI products is no longer only residing with individuals throughout the organization. Instead, it is on a strategic level with top management buy-in. This allows an organization to become an “intelligent organization”. One such recent example is BuzzFeed. In the midst of a layoff affecting 12% of its staff, the BuzzFeed CEO Jonah Peretti recently said that he intends for AI to play a larger role in the company’s editorial and business operations. He expects that AI will augment the employees in their creative processes in the short term, and in 15 years he expects AI and data to be able to create, personalize and animate the content itself. As a reaction to the news, the BuzzFeed stock price rose more than 150% on a single trading day.
The main thing that AI will unlock for intelligent organizations is increased automation. The last era of automation mainly centered around Robotics Process Automation (RPA), which are rule-based scripts instructed by humans. The new era will center around Generative AI in general and LLMs in particular and we will be able to go beyond rule-based scripts to automate more heterogeneous tasks without having to give explicit instructions. Tasks could include fraud detection, simpler customer service errands, content generation, meeting transcription, meeting summarization, analysis of legal documents, etc. In addition, LLMs will be used to augment people in organizations in ideation, discussion, problem-solving, and decision-making processes. This capability will be naturally integrated into the everyday tools that organizations are using, such as the likes of Slack, Zoom and Notion. In other words, LLMs will be able to listen in on ongoing conversations and contribute appropriately. If given enough permission, LLMs will be able to amass the conversed knowledge of entire organizations - putting an end to the time-consuming and costly knowledge silos that are haunting every organization today.
Most companies still are yet to figure out the long-term implications of generative AI for them. In fact, the management teams of most companies should devote a considerable effort to understand if and how they could leverage AI solutions to improve the way in which they carry out their tasks and services since it will become an important source of differentiation both in terms of improved service/product quality and cost.
Movements along the AI tech stack - single companies operating on the whole stack
Although we classify AI companies into different categories based on which part of the AI tech stack they focus on the most, the reality is not always that black and white. An AI company, regardless of category, is usually required to interact and work across the whole stack.

To begin with, training data (provided by an AI Enabler company) is used to train an LLM (done by an AI Core company), which in turn is leveraged to build some applications (done by an AI Native or AI Featured company). As already stated above, companies in the application layer have rich possibilities to collect user feedback data. This is exactly the kind of data needed for the reinforcement learning of LLMs. In other words, the companies that act in the application layer are often both application and data providers. The only missing part for them to own the whole tech stack going from the data to the application layer is the model layer. In fact, Jasper.ai recently announced that it is starting to build its own LLMs. This would make them own the entire value chain, going through the data, model, and application layer. Similarly, OpenAI started at the model layer. With the launch of ChatGPT, they entered the applications layer, through which they have been able to enter the data layer through the collection of human feedback training data. In other words, they have also started to own the entire value chain of the AI tech stack. We expect to see many more examples of this happening.
What’s next?
We hope that you, after reading this text, have acquired a foundational understanding of Generative AI in general and LLMs in particular. It is important to note that we are still very early in this new era and more progress will take place during the coming few years than we have seen during the last few decades. Feel free to engage with us through our Linkedin (Patrik Liu Tran & Pietro Casella) and subscribe to our Substack to stay tuned for more content in this series. Until then, we will leave you with eight noteworthy topics that warrants further exploration and discussion:
The era of the gold rush in Generative AI: After the big focus on web3 and crypto during 2022, investors and entrepreneurs have heavily shifted focus towards AI in general and generative AI in particular. We are currently seeing a lot of capital going into the space at commercial terms that reminds us very much of 2021. A natural question that comes to mind is: is this all hype with empty promises? Well, the field of AI has always been surrounded by high expectations and promises since its inception in 1956, and the inability to meet these expectations historically has led to multiple "AI winters" - periods characterized by a lack of funding and interest in the field. However, with the recent advancements in generative AI, it's clear that those days are behind us. For the right use cases, AI can provide a tremendous amount of value. The area might be overheated at worst, where we see some inflated valuations (and of course there might be investors who invest in things they don’t fully understand and thereby make bets that do not fully make sense). With that said, we strongly believe that the golden age of AI is here now.
Intelligent organizations and augmented employees: As discussed above, AI Powered companies are going to increase their productivity through automating tasks as well as improving their decision making abilities through the AI augmentation. A report indicates that Github Copilot increases the development speed by 55%, implying that the productivity of developers will increase significantly by leveraging AI models in their work. This is most likely only the start within code generation - LLMs will become better at generating code and we might enter a no-code era even among developers. Professions within other domains such as law, marketing, sales, customer service, etc. can expect a similar increase in productivity. Ultimately every company in every sector will sit down and think: What does this mean for us? Companies will either disrupt or be disrupted.
The rise of specialized models: As mentioned above, we expect that most value will come from specialized models as opposed to foundation models. Consequently, we believe that we will start to see much more specialized models emerging. A model does not need to know how to write poetry in the style of a rapper if it is intended to be used for customer service in a bank - instead you can build a much smaller model that is specialized for your domain(s) and/or task(s). In fact, we predict that it will be of the highest importance for AI Core companies such as OpenAI, AI21 and Cohere to develop features allowing their customers to easily specialize models on top of their foundation models - because this is what everyone is waiting for in order to unlock the next level of value from LLMs. In addition to achieving superior performance through specialized models, companies at the application layer will also gain a proprietary model that way, which makes them more than just a nice UX on top of a foundation AI model that anyone can access.
Multimodal models: Although we focused mainly on language models in this content piece and thereby text data, generative AI encompasses other modalities such as image and sound. A big thing that is currently happening is the attempts and efforts that are devoted towards combining different modalities in an AI model, meaning the construction of models that can take input from one or several modalities and provide output in one or several other modalities. One recent such example was provided by a team at Google Research, who published a paper showcasing how they translate text into music. This is powerful in its own right, empowering anyone with or without musical background to generate music based on descriptions in natural language. However, imagine if we couple this with image-to-text-capabilities. That would open up for use cases where an AI model analyzes what is shown throughout a video and then describes that in text for an AI model to generate suitable music. Conversely, let’s say that you have generated music through text prompts and now want to create a suitable music video. All of that can potentially be done with a single instruction given to a multimodal model.
When Jensen Huang, Founder and CEO of Nvidia, was visiting Sweden in January 2023, we spoke to him about what Nvidia is focusing on going forward within generative AI. One of the important things he mentioned was their effort to create multimodal models as opposed to previous efforts such as MT-NLG that focused on a single modality.
Jensen and Patrik talking about AI The importance of reinforcement learning through human feedback: Although methods for Reinforcement Learning through Human Feedback have existed for many years, their impact on the performance of LLMs are yet to be thoroughly understood.
Our prediction is that GPT4 will achieve a step change in performance over GPT3 mainly through increased volumes of training data for both initial training and reinforcement learning. Thanks to the popularity of ChatGPT, OpenAI has managed to amass an unprecedented scale of human feedback for reinforcement learning. Although the relative importance between data for initial training vs. human feedback data for reinforcement learning has not yet been thoroughly investigated, it would not surprise us if the reinforcement learning part will turn out to be the secret sauce for GPT4. It is also the most proprietary part of OpenAIs training data for LLMs currently.Scale matters: Application companies can collect relevant human feedback for reinforcement learning as discussed in section above. If the prediction we make in point 5 above is roughly right regarding the importance of human feedback data, then the companies with large scaled consumer applications that can reach many users will be able to amass large amounts of proprietary and critical data for model improvement. As a result, companies such as Meta, Google, Apple, Amazon, Alibaba, and Wechat with large customer-facing applications should not yet be dismissed in the race to dominate AI - even though every other media outlet seems to conclude that Microsoft is a given winner due to its partnership with OpenAI. Remember, the only really proprietary alternative to improve large language models relates to data - larger model size and better architecture (given that they are published in research articles) can be copied.

More companies will be evaluated as data companies: Given the importance of conversational data for training LLMs, companies that can collect this kind of data at scale will be highly valued. For example, one of the largest datasets of conversational data is collected by Twitter. The model behind ChatGPT was trained on Twitter data - something that Elon Musk put a stop to as soon as he learnt about it. Maybe, a significant part of Twitter’s value in the future will come from selling access to the conversational data? Other businesses that have access to large amounts of conversational data is Meta, which offers applications such as Facebook, Instagram and Whatsapp. What would the conversational data of Meta be worth if it would be a stand-alone business?
Ethical and Societal implications of AI will continue to dominate the public and regulatory debate: Discussions on topics such as copyright issues, trustworthiness of models, labour issues and cybersecurity have sparked immense debate already and are likely to trigger reactions from regulators. Companies will need to carefully navigate the regulatory landscape and we already see many examples of regulations that will come, such as EU AI Act and China’s ban on non-watermarked AI generated media. It is going to be an uncertain time when it comes to regulation, and until we have clarity on that, we hope that everyone in the space will do their part in being ethical and fair in their application of AI.

Thank you for reading, we had a lot of fun writing this for you, and there’s a lot more coming up. If you enjoyed this, please subscribe to read our upcoming articles.
Also, we would love it if you could share this with
friends, colleagues, and network 🙏 and of course reach out to us on
Linkedin (Patrik Liu Tran, Pietro Casella) where we’re continuing the conversation!
Your article is very enlightening! I'm wondering if we can translate this blog in Chinese and post it on our WeChat official platform. We will keep the original link and state where it is translated from. Thank you!
Such an insightful post. Thanks a lot for sharing!